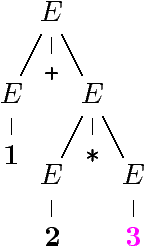Grammaires algébriques
Analyse grammaticale.
Grammaires algébriques
Une grammaire algébrique (context-free) est un quadruplet
(Σ, V, S, P) avec :
-
Σ est l'alphabet des terminaux a, b etc. (ou lexèmes, ou
tokens),
- V est l'alphabet des non-terminaux A, B, etc. (disjoint de Σ),
- S ∈ V est le symbole de départ,
- P est un ensemble de productions A → α.
Notations
-
Γ, Δ, etc. designe un caractère de Σ ∪ V.
- α, β, etc. désigne un mot de (Σ ∪
V)∗ (sauf є, mot vide).
- A → α1 ∣ … αn désigne A → α1, … , A → αn
Langages algébriques
Une grammaire G définit le langage L(G) sur Σ.
Les mots de L(G) sont engendrés à partir de S et en appliquant les
productions jusqu'à plus soif (en dérivant S).
-
Application d'une production au mot αAβ.
|
αAβ ⇒ αγβ, avec
A → γ ∈ P.
|
- Si S ⇒*w (fermeture reflexive et transitive de
⇒) avec w ∈ Σ ∗, alors w ∈
L(G).
Exemple Σ = {int, (, ), +, -, *,
/}, V = {E}, départ en E et
|
E → E + E E → E - E E → E * E E → E / E |
|
E → ( E ) E → int
|
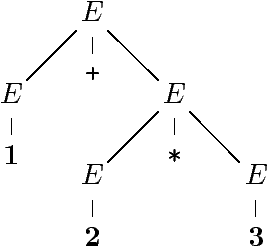
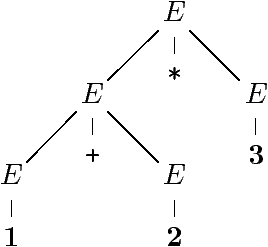
Example (suite)
Trois dérivations de la même expression arithmétique
1 + 2 * 3
(1, 2 et 3 sont des entiers int).
|
E ⇒
E + E ⇒
E + E * E ⇒
1 + E * E ⇒
1 + 2 * E ⇒
1 + 2 * 3 |
|
|
| E ⇒
E * E ⇒
E + E * E ⇒
1 + E * E ⇒
1 + 2 * E ⇒
1 + 2 * 3 |
|
|
| E ⇒
E + E ⇒
1 + E ⇒
1 + E * E ⇒
1 + 2 * E ⇒
1 + 2 * 3
|
« Sens » des dérivations :
|
7 ⇒
1 + 6 ⇒
1 + 2 * 3
9 ⇒
3 * 3 ⇒
1 + 2 * 3
7 ⇒
1 + 6 ⇒
1 + 2 * 3
|
Un sens grammatical, arbres de dérivation
Seul l'arbre final compte
Le mot 1 + 2 * 3 est dans L(G)
Avec deux sens distincts :
L'arbre de dérivation ressemble à un AST (en plus riche).
De même, seules les dérivations gauches (ou droites) comptent.
Pour la compilation...
L'ambiguïté est nuisible.
-
Le sens de la syntaxe concrète n'est plus clair.
- Les analyseurs sont déterministes de toute façon.
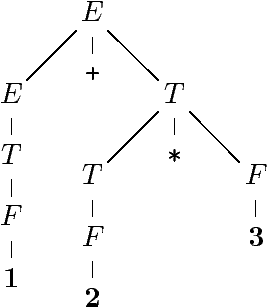
Il faut G' équivalente à G --- L(G) = L(G'), et non-ambigüe --- un seul
arbre de dérivation (une seule dérivation gauche, droite).
Cf. la grammaire usuelle des expression
arithmétiques.
|
E → E + T E → E - T E → T |
|
|
T → T * F T → T / F T → F |
|
|
F → ( E ) F → int
|
Écrire un analyseur
Un premier essai avec G' :
Non-terminaux ∼ appels de fonctions,
terminaux ∼ consommation de lexèmes dans un flux.
Lire la grammaire comme la définition de fonctions récursives.
Ici ça doit rater, pourquoi ?
Recommençons
|
E → T + E E → T - E E → T
|
|
|
T → F * T T → F / T T → F
|
|
|
F → ( E ) F → int
|
Et là ça fonctionne.
let rec expr flux =
term flux ;
begin match look flux with (* Regarder le lexème de tête *)
| (ADD|SUB) -> eat flux (* le manger *); expr flux
| _ -> ()
end |
|
and term flux =
factor flux ;
begin match look flux with
| (MUL|DIV) -> eat flux ; term flux
| _ -> ()
end
and factor flux = match look flux with
| INT _ -> eat flux
| LPAR ->
eat flux ; expr flux ; is RPAR flux (* vérifier et manger RPAR *)
| _ -> raise Error |
|
Analyse LL(1)
Left-to-right parse, Leftmost derivation, (1-token lookahead).
Une compilation des grammaires vers les analyseurs, avec pour cible :
-
Une fonction (qui prend un flux) par non-terminal.
- Les fonctions commencent par match look flux with...
- Les actions du filtrage sont des séquences traduites des
membres droits :
-
A ↦ A flux .
- token ↦ is TOKEN.
- Les filtrages se terminent obligatoirement par
la clause
| _ -> raise Error.
Autrement dit, on se décide seulement au début de l'appel et on examine tous
les lexèmes possibles.
Première étape
Éliminer les cycles A → A qui partent tous seuls.
Éliminer la récursion gauche
Transformer
A → Aα1 ∣ … ∣ Aαn ∣ β1 ∣ …
βm
en
|
A → β1A0 ∣ … βmA0 A0 → α1A0 ∣ … ∣ αnA0 ∣ є
|
Généralisable aux cycles et à la récursion gauche indirects :
A ⇒*Aα.
Élimination de la récursion gauche
Partons de :
|
S → E eof |
|
E → E + E E → E - E E → T |
|
T → T * T T → T / T T → F |
|
F → ( E ) F → int
|
|
E → T E0 |
|
E0 → + T E0 ∣ - T E0 ∣ є |
|
T → F T0 |
|
T0 → * F T0 ∣ / F T0 ∣ є |
|
F → ( E ) ∣ int
|
Se decider entre les membres droits
Définissons FIRST, de (Σ ∪ V)∗ dans Σ ∪
{є}.
| FIRST(α) = { a ∈ Σ ∣ α |
|
aβ }
(∪ {є} si α ⇒*є)
|
| FOLLOW(A) = {a ∈ Σ ∣ S |
|
αAaβ}
|
On se décide entre deux productions non-vides A → α ∣ β si
FIRST(α) ∩ FIRST(β) = ∅.
On peut appliquer la production vide A → є si
le lexème examiné est dans FOLLOW(A).
Calcul de FIRST et FOLLOW
|
FIRST(є) = {є} |
|
FIRST(a) = {a} |
|
|
FIRST(A) = FIRST(α1) ∪ … ∪
FIRST(αn), quand A → α1 ∣ … ∣ αn |
|
FIRST(Γα) = FIRST(Γ), si є ∉FIRST(Γ) |
|
FIRST(Γα) = (FIRST(Γ)\ { є }) ∪
FIRST(α), si є ∈ FIRST(Γ)
|
| Production |
|
Contrainte |
| A → αBβ |
|
(FIRST(β)\ {є}) ⊆ FOLLOW(B) |
| A → αB |
|
FOLLOW(A) ⊆ FOLLOW(B) |
| A → αBβ, avec є ∈ FIRST(β) |
|
FOLLOW(A) ⊆ FOLLOW(B) |
Calcul de FIRST
|
E → T E0 |
|
E0 → + T E0 ∣ - T E0 ∣ є |
|
T → F T0 |
|
T0 → * F T0 ∣ / F T0 ∣ є |
|
F → ( E ) ∣ int
|
|
F1(F) = F0(( E )) ∪ F0(int) ∪ F0(F) =
{(, int} |
|
F1(T0) = F0(* F T0) ∪ F0(/ F T0) ∪
F0(є) ∪ F0(T0) = {*, /, є} |
|
F1(E0) = F0(+ T E0) ∪ F0(- T E0) ∪
F0(є) ∪ F(E0) = {+, -, є}
|
|
F1(T) = F0(F T0) ∪ F0(T) = ∅ |
|
F1(E) = F0(T E0) ∪ F0(E) = ∅
|
|
F2(F) = {(, int} F2(T0) = {*, /, є} F2(E0) = {+, -, є} (changent pas) |
|
F2(T) = F1(F T0) ∪ F1(T) = {(,
int} (є ∉F1(F)) |
|
F2(E) = F1(T E0) ∪ F1(E) = ∅
|
|
F3(F) = {(, int} F3(T0) = {*, /, є} F3(E0) = {+, -, є} |
|
F3(T) = {(, int} F3(E) = {(, int}
|
Un calcul plus intelligent
|
⋮ |
|
Fn+1(T) = Fn+1(F T0) ∪ Fn(T) =
Fn+1(F) ∪ Fn(T) (є ∉Fn(F)) |
|
Fn+1(E) = Fn+1(T)
|
Résultat
| |
FIRST |
FOLLOW |
| S |
(, int |
|
| E |
(, int |
), eof |
| E0 |
є, +, - |
), eof |
| T |
(, int |
), +, -, eof |
| T0 |
є, *, / |
), +, -, eof |
| F |
(, int |
), +, -, *, /, eof |
-
Pour toutes les A → α,
mettre α dans les case de la
la colonne a pour tous les a de FIRST(α).
- En outre, si є est dans FIRST(α),
mettre α dans les cases de la colonne a pour tous
les a de FOLLOW(A).
Table d'analyse prédictive
| |
int |
( |
) |
+ |
- |
* |
/ |
eof |
| S |
E eof |
E eof |
|
|
|
|
|
|
| E |
T E0 |
T E0 |
|
|
|
|
|
|
| E0 |
|
|
є |
+ T E0 |
- T E0 |
|
|
є |
| T |
F T0 |
F T0 |
|
|
|
|
|
|
| T0 |
|
|
є |
є |
є |
* F T0 |
/ F T0 |
є |
| F |
int |
( E ) |
|
|
|
|
|
|
-
Case vide ↦ une erreur à l'analyse.
- Pas de doublons dans les cases, la grammaire est LL(1).
Analyseur LL(1)
let rec start flux = match look flux with
| INT _|LPAR -> expr flux ; is EOF flux
| _ -> raise Error
and expr flux = match look flux with
| INT _|LPAR -> term flux ; expr0 flux
| _ -> raise Error
and expr0 flux = match look flux with
| ADD -> is ADD flux ; term flux ; expr0 flux
| SUB -> is SUB flux ; term flux ; expr0 flux
| RPAR|EOF -> ()
| _ -> raise Error |
|
and term flux = match look flux with
| INT _|LPAR -> facteur flux ; term0 flux
| _ -> raise Error
and term0 flux = match look flux with
| MUL -> is MUL flux ; facteur flux ; term0 flux
| DIV -> is DIV flux ; facteur flux ; term0 flux
| RPAR|EOF|ADD|SUB -> ()
| _ -> raise Error
and factor flux = match look flux with
| INT i -> is (INT i)
| LPAR -> is LPAR ; expr flux ; is RPAR flux
| _ -> raise Error |
|
Une grammaire non-ambigüe et non-LL(1)
Grammaire :
|
S → E eof E → T + E E → T T → F * T T → F F → ( E ) F → int |
|
|
| |
int |
( |
) |
+ |
* |
eof |
| E |
T, T + E |
T, T + E |
|
|
|
|
| T |
F, F * T |
F, F * T |
|
|
|
|
| F |
int |
( E ) |
|
|
|
|
|
|
Solution : factoriser
Remplacer E → T ∣ T + E par
E → T E0 et E0 → є ∣ + E.
|
S → E eof E → T E0 E0 → є E0 → + E T → F T0
T0 → є T0 → * T F → int F → ( E ) |
|
|
| |
int |
( |
) |
+ |
* |
eof |
| E |
T + E0 |
T + E0 |
|
|
|
|
| E0 |
|
|
є |
+ E |
|
є |
| T |
F * T0 |
F * T0 |
|
|
|
|
| T0 |
|
|
є |
|
* T |
є |
| F |
int |
( E ) |
|
|
|
|
|
|
LL, le bilan
LL(k) : examiner k lexèmes d'avance (tables potentiellement énormes).
Pour :
-
Simple à comprendre.
- Guide pour écrire les analyseurs à la main.
- On peut concevoir les langages de programmation avec des
grammaires LL (cf Pascal).
Contre (pour la production automatique d'analyseurs).
-
Il y a plus puissant (LR).
- Transformations de la grammaire nécessaires.
Automate shift-reduce
Une nouvelle cible :
-
Ils ont une pile de symboles de Σ ∪ V.
- Ils lisent un flux de lexèmes.
Les actions possibles :
-
shift, ie. consommer et empiler un lexème, ou
- reduce, ie. réduire une règle.
Cela revient à appliquer une règle de production sur le sommet (partie
droite) de la pile.
Les automates LR cherchent à déterminiser le processus.
Exemples d'éxecution de l'automate shift-reduce
Dans la grammaire :
|
E → E + E E → E - E E → E * E E → E / E |
|
E → ( E ) E → int
|
Trouver les deux dérivations :
Bizarrement, l'automate à pile construit une dérivation droite.
La première
|
|
| Pile |
Flux |
Action |
Production |
| |
1 + 2 * 3 |
shift |
|
| 1 |
+ 2 * 3 |
reduce |
E → int |
| E |
+ 2 * 3 |
shift |
|
| E + |
2 * 3 |
shift |
|
| E + 2 |
* 3 |
reduce |
E → int |
| E + E |
* 3 |
|
|
| E + E * |
3 |
shift |
|
| E + E * 3 |
|
reduce |
E → int |
| E + E * E |
|
reduce |
E → E * E |
| E + E |
|
reduce |
E → E + E |
| E |
|
|
|
|
|
La seconde
|
|
| Pile |
Flux |
Action |
Production |
| |
1 + 2 * 3 |
shift |
|
| 1 |
+ 2 * 3 |
reduce |
E → int |
| E |
+ 2 * 3 |
shift |
|
| E + |
2 * 3 |
shift |
|
| E + 2 |
* 3 |
reduce |
E → int |
| E + E |
* 3 |
|
E → E + E |
| E |
* 3 |
shift |
|
| E * |
3 |
shift |
|
| E * 3 |
|
reduce |
E → int |
| E * E |
|
reduce |
E → E * E |
| E |
|
|
|
|
|
Comment déterminiser (shift ou reduce ?)
Avec la grammaire usuelle (non-ambigüe).
L'automate devrait pouvoir se décider :
-
À l'aide du sommet de la pile,
- En fonction du lexème en attente.
Le contrôle devrait pouvoir être confié à un automate fini.
Sur l'exemple (grammaire usuelle des expressions arithmétiques).
-
Comment choisir E ⇒*1, T ⇒*2,
F ⇒*3 ?
- Comment choisir shift, à l'étape critique signalée.
| Pile |
Flux |
Action |
Production |
| |
1 + 2 * 3 |
shift |
|
| 1 |
+ 2 * 3 |
reduce |
F → int |
| F |
+ 2 * 3 |
reduce |
T → F |
| T |
+ 2 * 3 |
reduce |
E → F |
| E |
+ 2 * 3 |
shift |
|
| E + |
2 * 3 |
shift |
|
| E + 2 |
* 3 |
reduce |
F → int |
| E + F |
* 3 |
reduce |
T → F |
| E + T |
* 3 |
|
|
| E + T * |
3 |
shift |
|
| E + T * 3 |
|
reduce |
F → int |
| E + T * F |
|
reduce |
T → T * F |
| E + T |
|
reduce |
E → E + T |
| E |
|
|
|
Écrire un analyseur LR à la main
|
S → E eof |
|
E → E + E |
|
E → int |
|
type symbol = E | T of token |
|
let rec auto stack flux =
match look flux, stack with
…
and shift stack flux =
let tok = look flux in
eat flux ; auto (T tok::stack) flux |
|
Un automate possible
let rec auto stack flux = match look flux, stack with
(* Accepter l'entrée *)
| EOF, [E] -> ()
| ADD, [E] -> shift stack flux
(* Réduction de E → E + E *)
| (ADD|EOF), E::T ADD::E::rem -> auto (E::rem) flux
(* Réduction de E → int *)
| (ADD|EOF), T (INT _)::rem -> auto (E::rem) flux
(* Shift de int *)
| INT _, (T ADD::E::_|[]) -> shift stack flux
(* N'importe quoi d'autre est une erreur *)
| _ -> raise Error |
|
Un autre automate possible
let rec auto stack flux = match look flux, stack with
(* Accepter l'entrée *)
| EOF, [E] -> ()
(* Toujours shifter + *)
| ADD, E::_ -> shift stack flux
(* Réduction de E → E + E *)
| EOF, E::T ADD::E::rem -> auto (E::rem) flux
(* Réduction de E → int *)
| (ADD|EOF), T (INT _)::rem -> auto (E::rem) flux
(* Shift de int *)
| INT _, ([]|T ADD::_) -> shift stack flux
| _ -> raise Error |
|
Automate LR(1)
-
Il y a en fait quatre actions,
shift, reduce(A → α) (la production réduite est
indiquée), accept (succès) et error (échec).
- Pile (Δi, si) d'états et de symboles de Σ ∪ V
(sauf le fond de pile s0, état initial)
- L'automate est déterminé par deux fonctions :
-
goto(s,Δ) vers les états,
- et action(s,a) vers les actions.
Avec une pile s0, (Δ1), …
(Δm, sm), l'automate (de contrôle) consulte le lexème a en attente et
selon la valeur de action(sm, a) effectue :
-
shift
-
Le lexème est consommé et (a, goto(sm, a)) est empilé.
- reduce(A → α)
-
L'automate dépile l eléments, où l est la longueur de α et
(A, goto(sm-l, A)) est empilé.
- accept ou error
-
L'automate signale le succès ou un échec.
Automate de contrôle
La fonction goto représente les transitions de l'automate de contrôle,
un de ses états I est un ensemble de configurations C.
une configuration C est une paire composée,
-
d'une production pointée A → α • β,
où A → αβ est une production,
- et du prochain lexème possible a après αβ.
Une configuration C décrit un état courant de l'automate
shift-reduce sous-jacent, avec
α en sommet de pile et un flux dont le début
dérive de βa.
Calcul des états et des transitions
La fermeture d'un ensemble de configurations est le
plus petit ensemble I contenant I et satisfaisant :
|
|
⎛
⎝ |
(A → α • B β, a) ∈ I
∧ B → γ ∈ G
∧ b ∈ FIRST (β a)
|
⎞
⎠ |
⇒ (B →• γ, b) ∈ I
|
Les transitions sont :
goto (I,Δ) =
fermeture
(
{(A → α Δ • β, a) ∣ (A → α • Δ β, a) ∈ I}
)
Le calcul est celui de la déterminisation des NFA,
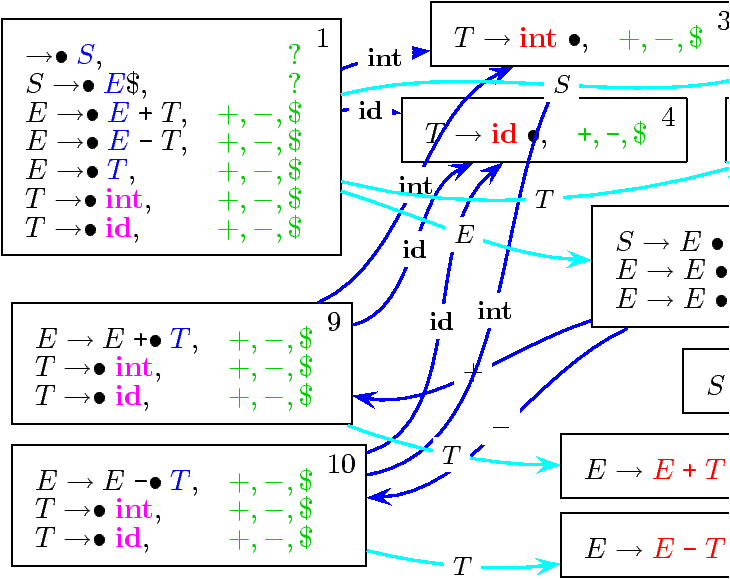
à partir de la configuration initiale « ( → • S, Σ) ».
Avec la grammaire :
|
→ S S → E $ E → E + T E → E - T E → T T → id T → int
|
Calcul des tables LR(1)
-
Si (A → α • a β, b) ∈ I
et goto (I, a) = J,
alors action (I,a) = shift
(on peut représenter simultanément goto(I,a) en écrivant shift(J)).,
- Si (A → α •, a) ∈ I, alors
action (I,a) = reduce (A → α).
Sauf, si A → α est l'axiome → S, auquel cas
action (I,a) = accept.
Si action(I,a) n'est pas défini par ces deux règles, alors on a
action(I,a) = error.
En cas de conflit, G n'est pas LR(1).
-
reduce/reduce
-
Lorsque (A → α•, a) ∈ I et (B → β•, a) ∈
I. Super grave.
- shift/reduce
-
Lorsque (A → α • a γ,b) ∈ I et
(B → β•, a) ∈ I, parfois moins grave (priorités).
LALR(1) et bilan
-
LR(1) généralisé en LR(k) (se décider sur k lexèmes).
- LALR(1) (yacc, bison etc.), « simplification »
de LR(1) : ignorer les a dans (A → α • β, a) et
fusionner les états.
Les tables sont plus petites (moins d'états).
- Bilan
|
LL(k) ⊂ LL(k+1) LR(k) ⊂ LR(k+1) LL(k) ⊂ LR(k) LALR(1) ⊂ LR(1)
|
En pratique : ocamlyacc (yacc adapté à Caml)
traite les grammaires LALR(1).
ocamlyacc
Source Nom.mly, objet
Nom.ml et
Nom.mli.
%{
open Ast
%}
/* Déclaration des lexèmes */
%token LPAR RPAR
%token ADD SUB MUL DIV
%token <int> INT
%token EOF
/* Point d'entrée */
%start expr
%type <Ast.t> expr
%% |
|
/* productions, avec actions */
expr:
expr1 EOF {$1}
;
expr1:
expr1 ADD expr1 {Binop (Add,$1, $3)}
| expr1 SUB expr1 {Binop (Sub,$1, $3)}
| expr1 MUL expr1 {Binop (Mul,$1, $3)}
| expr1 DIV expr1 {Binop (Div,$1, $3)}
| SUB expr1 {Binop (Sub, Int 0, $2)}
| INT {Int $1}
| LPAR expr1 RPAR {$2}
; |
|
Compilation de l'exemple
# ocamlyacc -v arith.mly
20 shift/reduce conflicts
Un analyseur est quand même produit.
Savoir (rare),
aller voir dans arith,output (option -v).
16: shift/reduce conflict (shift 10, reduce 2) on ADD
...
16: shift/reduce conflict (shift 13, reduce 2) on DIV
state 16
expr1 : expr1 . ADD expr1 (2)
expr1 : expr1 ADD expr1 . (2)
...
expr1 : expr1 . DIV expr1 (5)
E + E • op E vu comme
E + (E op E)
(shift gagne par défaut).
Solution par priorités
-
On donne des (niveaux de) priorités aux lexèmes.
La priorité d'une production est celle de son dernier lexème.
En cas de conflit, la plus forte priorité gagne.
- Pour les cas où la priorité est la même. Il y a une information
d'associativité, gauche (reduce gagne), droite (shift gagne),
aucune (error gagne).
Les priorités sont déclarées dans la deuxième section.
/* Des moins prioritaires aux plus prioritaires */
%left ADD SUB
%left MUL DIV |
|
En avons nous fini ?
Non ! et le moins unaire ? (pourtant ocamlyacc ne signale
plus de conflits).
État de réduction du moins unaire.
state 9
expr1 : expr1 . ADD expr1 (2)
expr1 : expr1 . SUB expr1 (3)
expr1 : expr1 . MUL expr1 (4)
expr1 : expr1 . DIV expr1 (5)
expr1 : SUB expr1 . (6)
MUL shift 12
DIV shift 13
. reduce 6
On veut - E • op E compris comme
(- E) op E dans tous les cas.
Solution
Définir une priorité, l'assigner à la règle du moins unaire.
%left ADD SUB
%left MUL DIV
/* left sans importance ici, car pas de lexème de cette priorité */
%left UMINUS
...
| SUB expr1 %prec UMINUS {Binexp (Sub, Int 0, $2)} |
|
Les Projets
Trois projets « classiques » :
-
Recibler vers Pentium/IA-32
- Construire un système à bytecode.
- Ajouter le passage par variable.
D'autres projets sont possibles...
Ce document a été traduit de LATEX par HEVEA
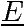 ⇒
⇒
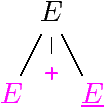 ⇒
⇒
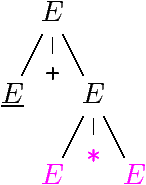 ⇒
⇒ 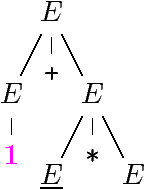 ⇒
⇒
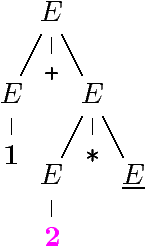 ⇒
⇒